Performance
SCAMP is extremely fast, especially on Tesla series GPUs. I belive this repository contains the fastest code in existance for computing the matrix profile. If you find a way to improve the speed of SCAMP, or compute matrix profiles any faster than SCAMP does, please let me know, I would be glad to point to your work and incorporate any improvements that can be made to SCAMP.
Notes on CPU performance
SCAMP’s CPU performance is very good. However, how performant it is depends heavily on the compiler and compiler flags used to build the SCAMP binary. Newer compilers are better at autovectorization, clang newer than v6 and gcc newer than v7 are best. MSVC tends to be much slower. Even with microoptimizations to generate better code based on the compiler, there can be up to a 10x (perhaps more) difference depending on the compiler you use. Though most of the time the variance is in the ballpark of less than 2x-3x difference.
The distributed pyscamp-gpu and pyscamp-cpu conda packages should have consistent good performance, as they are built with a modern compiler.
Precomputation performance
When enabling the --ultra_precision flag in the SCAMP CLI, or specifying the precision='ultra' option in pyscamp, the method for precomputing the necessary statisics for the matrix profile computation uses an O(nm) algorithm to compute the subsequence means and norms. This computation can become a bottleneck if you specify an extremely large subsequence length.
The timing results below do not use this option. All experiments were performed in double precision.
Benchmarks
SCAMP has automated benchmarks running. Here is a link to recent GPU performance results:
Note that the charts are not totally optimized for human consumption yet. But you can see a benchmark of each profile type.
Performance Comparisons
The included performance tests showcase SCAMP’s performance up to an input size of 16M datapoints; however, as we have shown in our publications SCAMP is scalable to hundreds of millions of datapoints and even billions of datapoints with the right hardware.
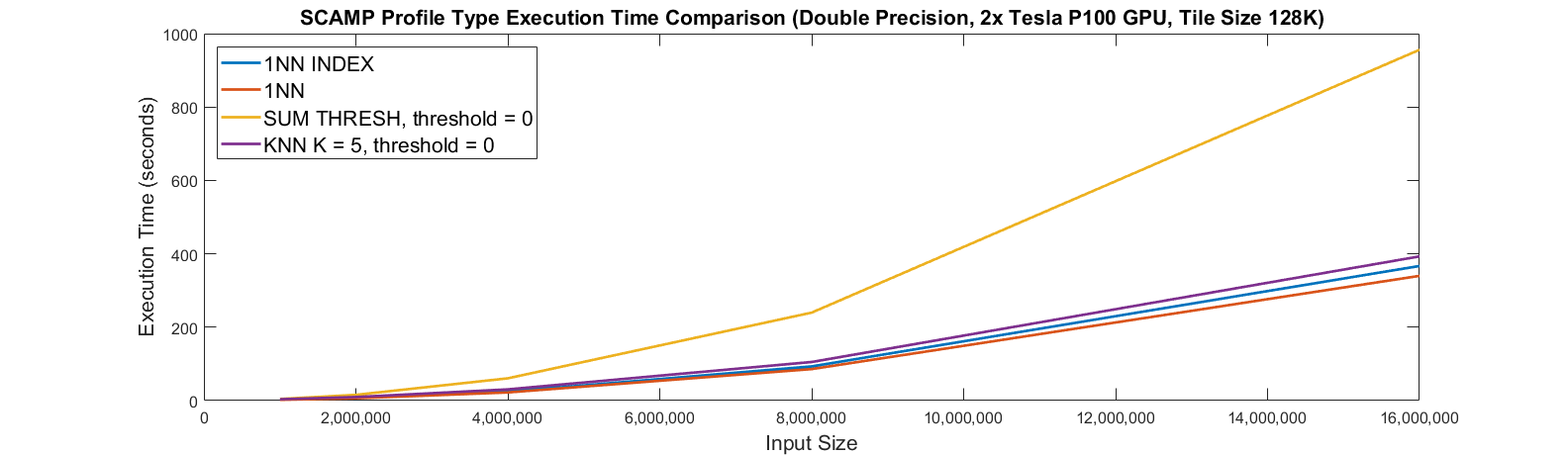
In the figure above we show the runtime in seconds for SCAMP’s various profile types (self-join) on 2 P100 GPUs.
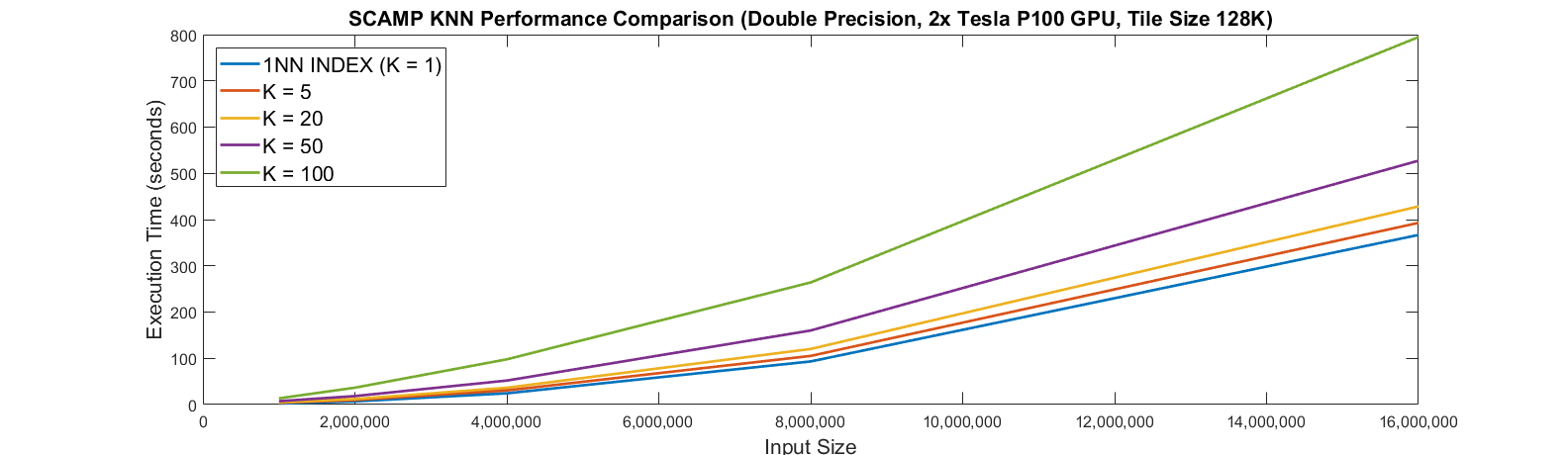
In the figure above we show the runtime in seconds for SCAMP’s approximate KNN (--profile_type=ALL_NEIGHBORS) matrix profile, while varying K and the input size on 2 P100 GPUs.
You can see that SCAMP maintains good performance relative to the baseline 1NN_INDEX matrix profile up to at least K=20, which should be sufficient for almost all practioners. All measurements were made with random data with the initial threshold set to 0 correlation (close to the worst case for KNN).
Performance Comparisons with other Matrix Profile Libraries
As mentioned before, SCAMP is extremely fast. This section contains experiments comparing other libraries to SCAMP in terms of performance to show quantitatively how fast SCAMP is. Note that these numbers reflect the performance of these libraries at a snapshot in time (June 2022) and implementations can change. If you want to reproduce these results, or generate new performance numbers in the future, the scripts used to generate the tables below are provided in the SCAMP repository here.
System 1 |
|
System 2 |
|
Note: Both CPUs have SSE2/AVX/AVX2/FMA enabled.
pyscamp vs stumpy Performance
stumpy is a very popular matrix profile library which has reimplemented many of the algorithms published by Eamonn’s time series lab at UC Riverside.
stumpy claims to have superior performance for the matrix profile algorithms they have reimplemented. However, these performance comparisons are done in bad faith. They compare across several generations of GPU/CPU hardware instead of making a fair apples to apples comparison, they simply copy numbers published in our papers and use hardware that is multiple generations newer, and throw many times more resources at the problem.
I contacted the stumpy maintainer years ago asking for these bad faith comparisons to be removed, but they refused. To set the record straight, here is a fair comparison of pyscamp and stumpy done on the same system.
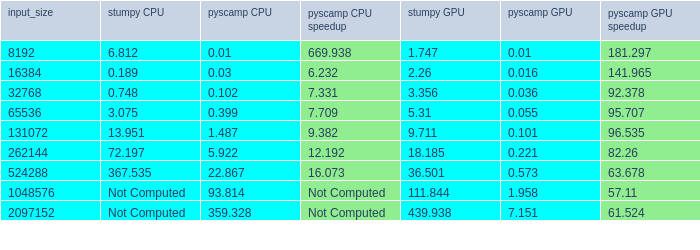
The tables below shows that pyscamp is faster than stumpy by a factor of 20x or more on the CPU, 6x faster on GeForce GPUs, and 60x faster using Tesla Series GPUs (pyscamp is even faster here because the bottleneck on GeForce cards is fp64 compute, GeForce cards are optimized for lower precision computation). Pyscamp has a single precision mode for GPU compute which makes GeForce performance better, but this is not reported to keep the playing field level.
Both systems are using the following dependencies installed from conda-forge: pyscamp-gpu v4.0.0 stumpy v1.11.1 python v3.9.12 cudatoolkit v11.6.0 numba v0.55.1 numpy v1.21.6 scipy v1.8.1
All GPU compute is done in FP64, FP32 numbers aren’t reported.
pyscamp vs stumpy (System 1: 20 logical cores, 1x GeForce RTX 3080)
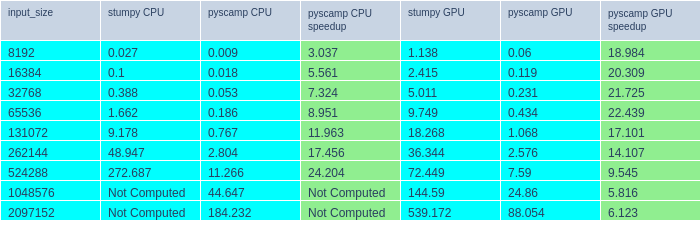
pyscamp vs stumpy (System 2: 12 logical cores, 2x Tesla P100)
pyscamp vs MPF
Matrix Profile Foundation’s matrixprofile is a python library which implements many of the matrix profile algorithms. It only supports CPU computation.
There are two algorithms in this library compared against:
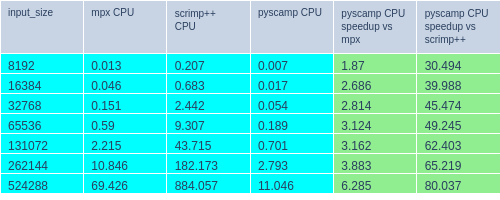
MPX: The mpx algorithm implemented in this library is very similar to what SCAMP uses and is also highly optimized, hence performance is similar here.
SCRIMP++: I show SCRIMP++ performance here for comparison even though it is an approximate algorithm and could be made faster by changing parameters. It is a common misconception that SCRIMP++ is always faster than exact algorithms like mpx and pyscamp. There are overheads assoicated with SCRIMP++ that have high constant factor overhead (e.g. repeated FFT computation) which high-performing exact algorithms like pyscamp don’t have. This can make pyscamp competetive with SCRMP++ in all but the most highly approximated scenarios.
Comparisons were done with 20 threads, SCRIMP++ was configured with 10% sampling and 25% step.
Packages installed: pyscamp-gpu v4.0.0 matrixprofile v1.1.10 python v3.8.13 numpy v1.22.4 scipy v1.8.1
pyscamp vs mpf (System 1: 20 logical cores, 1x GeForce RTX 3080)